How to extract data from PDF Documents with Scraping
A web scraping project may often involve collecting and downloading PDF files. However, extracting data from those files may or may not be part of the scraping process. Specifically, we’re talking about PDF scraping—a process that can be supported by basic tools or sophisticated ones involving artificial intelligence. But above all, the process requires the creativity and ingenuity of a team capable of developing the best strategy at the lowest possible cost and within the planned timeframe. On one end, there’s the “set of documents”; on the other, there is “valuable data and information.” In between, there’s a “box where things happen.” In this article, we’ll explore what happens inside that box to transform documents into usable data.
When is it worth automating PDF data extraction?
It comes down to volume and frequency—to gain an advantage or even to ensure the files are useful.
Consider these two examples:
- A spare parts vendor has several digitized technical manuals, each page containing specifications for a part or component.
- A law firm holds hundreds of thousands of scanned legal documents from various years and formats.
It’s common for such scanned manuals and documents to be in PDF format.
If there are only one or two files, a person could handle them. But when volume increases, automating the file processing becomes highly advantageous.
And if those files arrive on a regular basis (monthly, weekly, daily), automation is not just an advantage—it becomes essential for ensuring the utility of the documents.
PDF scraping techniques
Let’s go back to the concept of the “box where things happen.” One or more of the following techniques can be applied inside the box, either independently or as part of a more complex workflow. Unfortunately, there is no plug-and-play solution, so these techniques must be integrated into a customized and automated process—the so-called “box.”
We’ll group the techniques into three categories, which are not mutually exclusive and can be combined to meet different data needs:
- Structure and Metadata Processing
- Textual Content Processing
- Optical Character Recognition (OCR)
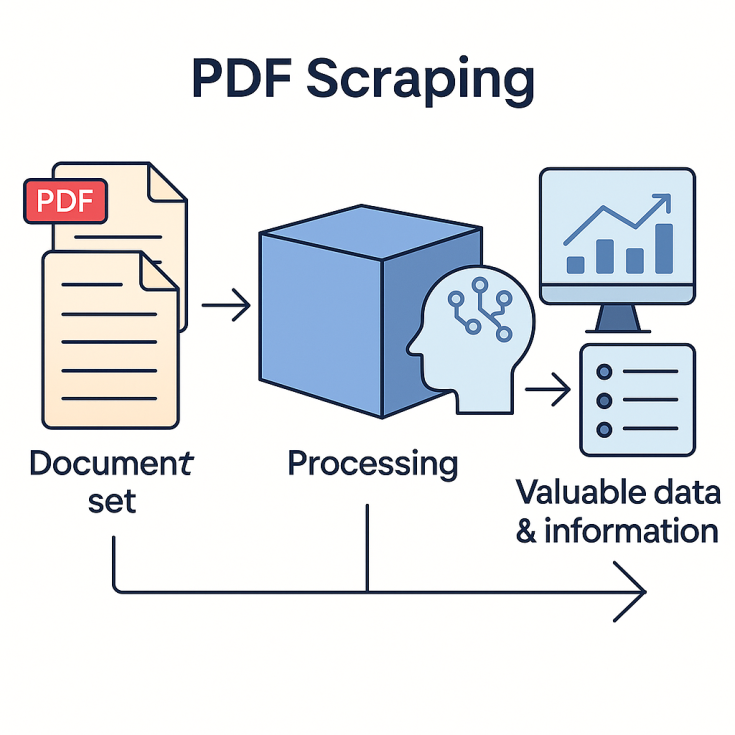
Some online applications allow users to process PDF files, but for large-scale analysis, these tools are impractical. Even AI-based services may be too costly or insufficient without proper preprocessing, categorization, and contextualization—or worse, unnecessary for the desired outcome.
Before diving into the techniques, let’s understand some key PDF characteristics that explain the different processing approaches.
A Portable Document Format (PDF) is known for universal compatibility. Unlike Excel or DOCX files, which may display differently on Linux, Mac, or across MS Office versions, a PDF looks the same on Windows, Linux, Mac, Android, etc., regardless of the viewer (Adobe, Foxit, etc.).
Because of this, PDFs are ideal for publishing and preserving:
- Font types and text styles
- Paragraph and page numbers
- Table dimensions
- Other visual elements
For scanned images, multiple pages can be combined into a single PDF instead of separate image files.
Now, let’s go over a general overview of processing techniques using the earlier examples: A) Spare parts vendor, and B) Law firm.
Structure and metadata processing
Like the tools used for creating and editing PDFs, the tools referenced here allow structural operations to be performed programmatically.
Structural manipulation includes rotating, adding or deleting pages, splitting or merging documents. While not data extraction per se, these steps often come first.
Metadata, if available, may include the document title (independent of file name), authors, creation or modification dates, keywords, and more.
These features help prepare the document to optimize more advanced tools and workflows.

Textual content processing
Tools like PDFMiner.six or pdfplumber allow you to read through a file’s pages and extract text to identify relevant information.
Imagine how useful this can be. A spare parts vendor might currently go page-by-page through a technical manual, copying and pasting product specs into an e-commerce platform.
Automation can streamline this by formatting the extracted data into CSV, JSON, or even loading it directly into a database.
Let’s expand our example: suppose a 2000-page file contains a table of contents between pages 3 and 8.
- Use a tool to extract the text from those pages.
- With plain Python, identify repeating patterns like:
"<title> ... <page number>".- Then, extract text from the rest of the document.
- Apply patterns to locate relevant details, such as:
– Component code
– Dimensions
– Category
If the data is in a table, locate the coordinates of each column’s label and use that to extract associated values below.
Finally, structure the data into a CSV or JSON file, where each row/item corresponds to a component with its description and source page number.
Optical character recognition (OCR)
OCR techniques often retrieve only part of the text from an image. They may skip letters, entire words, or even misinterpret content. Still, OCR is powerful—especially when full text is unnecessary, like in legal documents with repeating layouts or identifying seals.
There are lightweight, easy-to-install tools like EasyOCR, which comes with pre-trained models for multiple languages. More advanced (and expensive) tools like Google Cloud Vision AI can extract text from logos, handwritten notes, or signatures.
OCR can be enhanced with image processing: adjusting brightness or contrast, cropping specific regions (e.g., a judge’s stamp at the bottom, or the date in the top corner).
For our law firm example, let’s assume full transcriptions are not required. Instead, the firm needs a faithful digital copy that’s searchable.
Some useful indexing attributes might be:
- Document date
- Unique identifier
- Legal document type
Similar to the previous step (text content processing), you can define rules to extract this data. For example:
- Dates may appear in multiple formats (numeric or month names).
- Identifiers might follow a character count, use dashes, or be preceded by a keyword.
- The legal document type may be found in the title, stamp, or within a legal citation.
Conclusions
Let’s finally answer the article’s title question:
How to extract data from PDF documents with scraping?
Imagine you’re given a mission: you receive the most advanced, expensive smartwatch ever made, and a small nail. Your task? Hammer the nail into the wall.
You’ll quickly realize that, despite the futuristic tech, a primitive rock would do the job better.
So, the answer is:
Data is extracted by analyzing the source (PDF files), defining the desired output (valuable information), and creatively designing a solution that combines the chosen strategy with the appropriate tools.