Guide to data extraction methods using Python
Web scraping has become an essential technique for gathering data from websites in today’s data‑driven world. Whether you need to collect prices, reviews, content, or any other kind of information, Python offers a robust and versatile toolkit for doing so effectively. Data extraction now plays a crucial role in gaining competitive advantages, streamlining processes, and generating insights for business decisions. Whether you opt for off‑the‑shelf solutions or prefer to build custom tools, understanding the core principles—and the potential risks—will help you maximize benefits and avoid unpleasant surprises.
What does “data extraction” mean?
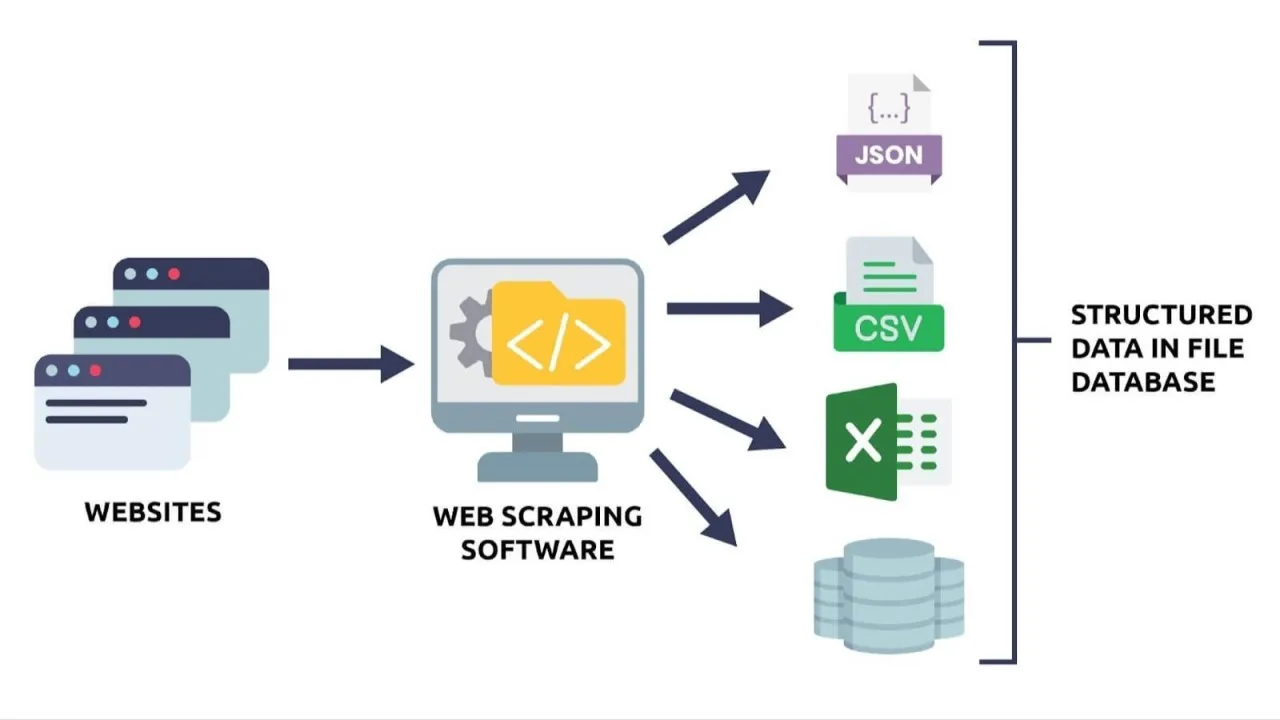
Data extraction is the practice of obtaining information from unstructured or semi‑structured sources (such as web pages, PDF documents, databases, or APIs) and transforming it into structured formats (CSV, JSON, or relational databases) as needed. This is often referred to as ETL (extract, transform, load).
Put simply, it involves capturing “raw” data and converting it into an organized, useful form that is ready for analysis or decision‑making.
A common example would be creating a CSV file with organized columns such as: product name, price, stock status, image links, available colors, dimensions, detailed description, category, and product URL. This single file would consolidate information for every item listed on an e‑commerce site—simplifying inventory management, enabling data analysis, and allowing seamless integration with other e‑commerce tools.
Common use cases
- E‑commerce: monitoring prices and analyzing competitors’ product offerings
- Investments and finance: harvesting market data, reviewing financial statements, and collecting economic news (e.g., real‑estate tracking, cryptocurrency prices, events, betting odds)
- Academic research: large‑scale collection of scientific papers, patents, and government statistics (e.g., press articles, public tenders)
- Marketing and sales: identifying potential leads and evaluating social‑media sentiment (e.g., gathering contact data such as emails or phone numbers, tracking likes around a topic, extracting social‑media comments)
- Media monitoring: tracking mentions across news outlets and digital platforms
How to choose the right service for your needs
Because automation projects vary widely in scope, selecting the right service can spell the difference between success and wasted resources. Keep these key factors in mind:
- Identify your specific needs
Define exactly what you want to collect. Is it a one‑off data grab or an ongoing feed? Clarity here prevents overspending on unnecessary solutions. - Assess volume and scalability
Determine whether you need a quick, small‑scale job or a well‑structured system that supports periodic extractions and grows with your project. - Consider technical requirements
Decide whether you only need raw data or also require tools to process and analyze it. AutoScraping, for instance, can provide both approaches. - Analyze your budget
If funds allow, a custom‑built tool tailored to your exact needs may be worthwhile. If cost optimization is crucial, SaaS platforms (Apify, Octoparse, ParseHub, Bright Data, etc.) offer ready‑to‑deploy solutions with low upfront expense. - Prioritize legality and compliance
Ensure your chosen solution respects legal regulations and data agreements. Research local and industry‑specific data laws to avoid violations.
At AutoScraping, our web‑scraping professionals walk through each of these steps to design the most efficient architecture for your project. We provide the necessary infrastructure, with special attention to scalability, efficiency, budget, and your project’s unique requirements.
Core web‑scraping methods in Python
Below we examine the most widely used techniques, from basic approaches to advanced strategies for handling dynamic pages and access restrictions.
Requests + BeautifulSoup: the classic approach
What is it?
The simplest and most common method. requests retrieves the page’s HTML, and BeautifulSoup (or lxml) parses it so you can extract data. With lxml, you can also use XPath queries.
Pros
- Quick to implement
- Ideal for static sites
- Easy to learn
Cons
Difficult to manage complex interactions
2. Selenium: browser automation
What is it?
Selenium controls real browsers (Chrome, Firefox, etc.) that render JavaScript, letting you interact with sites the way a user would—clicking, scrolling, filling forms, running scripts, opening tabs, and more.
Pros
- Works with dynamic sites
- Excellent for pages that load data via JS
Cons
- Slower and more resource‑intensive
- More complex setup and maintenance
3. Playwright: modern and versatile
What is it?
A newer alternative to Selenium for browser automation and control, with multi‑language support (including Python) and a highly efficient API.
Pros
- Built‑in parallel scraping
- Generally faster than Selenium
- Strong support for captchas and dynamic sites
Cons
- Requires a slightly more technical installation (Node.js + bindings)
- Steeper initial learning curve
4. Scrapy: a professional web‑extraction framework
What is it?
A full‑featured framework for large‑scale scraping. Ideal for building organized crawlers, managing pipelines and middlewares, and exporting data efficiently.
Pros
- Scalable and production‑ready
- Perfect for large projects
- Native asynchronous and parallel processing
Cons
- Overkill for very simple tasks
- More complex for beginners
Overcoming common obstacles
In web automation and analysis, you’ll encounter technical challenges that can slow progress. Knowing how to bypass them is key.
- CAPTCHAs – Use solvers such as AntiCaptcha or 2Captcha, or other auto‑resolution platforms to streamline the process.
- IP blocking – Rotate proxies—residential or datacenter—to hide your real IP, enabling smoother navigation and reducing block risk.
- User‑Agent and headers – Spoofing or rotating these values makes your requests look like genuine user activity.
- JavaScript‑heavy sites – Tools like Selenium or Playwright can render JS and interact with such pages effectively.
- Cookies – Some sites require specific cookies for access; managing them is vital, especially when using
requests.
Additional useful libraries
- lxml – extremely fast and efficient HTML/XML parser
- pandas – excellent for storing and analyzing data
- fake_useragent – handy for generating random request headers
- httpx or aiohttp – great choices for asynchronous HTTP requests
Python offers a vast range of tools for web scraping—everything from simple options for static pages to advanced frameworks for large‑scale crawling. Start with the approach that best fits your project’s current needs, and always respect website terms of service and applicable laws.
This is only a brief guide covering the most common methods; many other techniques are available and not described here.