Are you aware of the disadvantages of web scraping that can impact your business? While this technique offers valuable data extraction opportunities, it comes with significant challenges and risks that can lead to complications.
In this article, we'll explore the various drawbacks of web scraping, including legal issues, technical limitations, and ethical concerns. Understanding these challenges is crucial for businesses looking to utilize web scraping effectively.
By the end of this article, you will gain insights into the potential risks of web scraping and how to navigate them to protect your organization and maintain data integrity.
What is Web Scraping and Why is it Used?
Web scraping is the automated process of extracting data from websites.
This technique is widely utilized by businesses and developers to gather information quickly and efficiently, transforming unstructured web data into structured formats for analysis.
By leveraging web scraping, companies can obtain insights that drive strategic decision-making, enhance competitiveness, and streamline operations.
Here are some common uses of web scraping:
- Market Research: Collecting data on competitors, pricing, and product availability to inform business strategies.
- Content Aggregation: Gathering news articles, reviews, or social media posts to provide comprehensive insights.
- Lead Generation: Extracting contact information and details about potential customers for targeted marketing campaigns.
At AutoScraping, we understand the complexities of web scraping and strive to offer solutions that not only simplify the process but also address the common pitfalls.
By taking a thoughtful approach to data extraction, businesses can maximize their data's value while minimizing potential legal and technical complications.
Recommended Lecture: Alternatives to Web Scraping
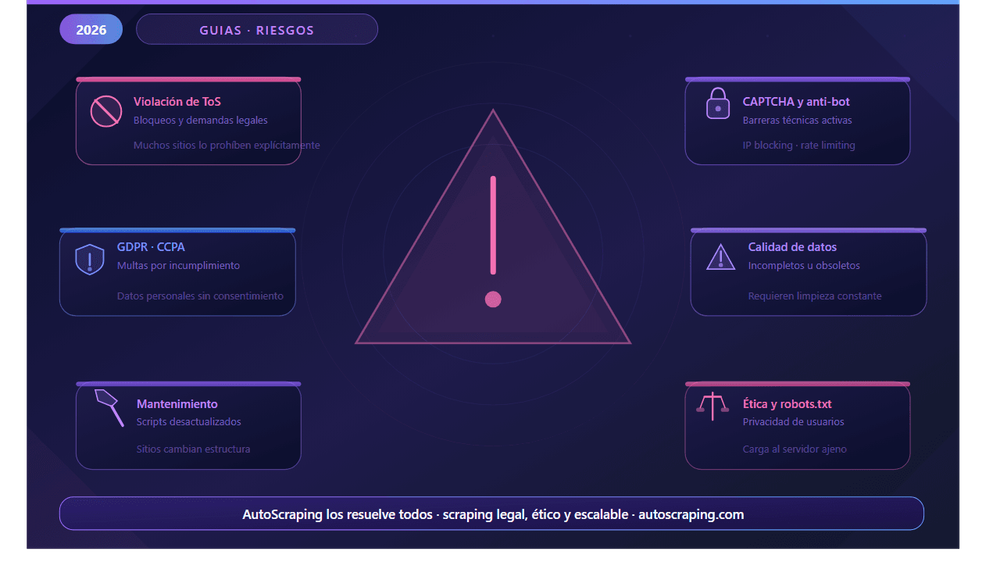
Disadvantages of Web Scraping for Businesses and Developers
While web scraping can be a powerful tool for data extraction, it comes with several disadvantages that businesses and developers need to consider. One significant concern is the legal risks associated with scraping data from websites.
- Violation of Terms of Service: Many websites explicitly prohibit scraping in their terms of service, and ignoring this can lead to lawsuits or account bans, including fines or being blocked.
- Data Privacy Laws: Regulations like the GDPR impose strict guidelines on how personal data can be collected and used. Non-compliance can damage a company's reputation and result in hefty penalties.
Additionally, web scraping may inadvertently infringe on data privacy laws. For instance, regulations like the GDPR in Europe impose strict guidelines on how personal data can be collected and used.
Failing to comply with these laws can not only damage a company's reputation but also result in substantial financial penalties. This highlights the importance of ensuring that your scraping practices are ethical and compliant with legal standards.
Furthermore, the technical challenges of web scraping cannot be ignored. Websites often employ various techniques to prevent scraping, such as CAPTCHA or dynamic content loading, which can complicate the extraction process:
- Prevention Mechanisms: Many websites use measures like CAPTCHA, IP blocking, or rate limiting to thwart scraping attempts.
- Higher Maintenance Costs: Regular updates may be necessary to adapt to changes in the website's structure or layout, demanding ongoing resources and attention from your development team.
Technical Limitations of Web Scraping
Web scraping, while a useful method for data extraction, faces several technical limitations that can hinder its effectiveness.
| Technical Limitations of Web Scraping | Description |
|---|---|
| Challenges with Dynamic Websites | Complex Data Structures: Data may be rendered on the client side, requiring scraping tools to simulate a browser environment to access the information.<br><br>Slower Extraction Rates: Additional processing time needed for dynamic sites can slow down data extraction, reducing efficiency for time-sensitive projects. |
| Maintenance Costs | Frequent Updates Needed: Developers must continuously monitor target websites for changes and update scraping scripts to maintain data accuracy.<br><br>Resource-Intensive: Ongoing maintenance can consume significant developer time and resources, increasing operational costs. |
| Inconsistent Data Quality | Inconsistent Data Availability: Changes in the target website's layout or structure can cause scraping scripts to fail, resulting in incomplete datasets.<br><br>Data Quality Issues: Without validation and cleaning, the extracted data may be outdated or irrelevant, requiring additional effort to meet business needs. |
Quality and Accuracy Issues
One of the main concerns with web scraping is data inconsistencies. When gathering data from various websites, it's common to encounter incomplete or outdated information, which can lead to significant challenges for businesses.
- Incomplete Data Sets: Changes in website structure can cause scraping tools to miss key information, resulting in gaps in the data collected.
- Outdated Information: Websites that frequently update their content may lead to stale data, making your insights less relevant.
Another challenge lies in the processing of scraped data. After extraction, the raw data usually requires substantial cleaning and validation to be useful.
- Data Cleaning Needs: Scraped data often contains errors or duplicates, necessitating careful review and correction.
- Resource-Intensive Work: The time spent on data cleaning can strain resources, which could be better allocated elsewhere.
Finally, the accuracy of the scraped data is critical. Businesses that rely on flawed information may make poor decisions that affect their bottom line.
- Consequences of Bad Data: Misguided strategies based on inaccurate data can waste time and resources.
- Need for Ongoing Validation: To ensure reliability, businesses must continuously monitor and validate scraped data, complicating the overall process.
Ethical Considerations
When it comes to web scraping, ethical considerations are critical. Scraping data without considering the website's terms of service can create serious issues.
Each website has its own rules about how its content can be used, and ignoring these rules is not only disrespectful but can also lead to consequences like legal action or being banned from the site.
- Follow Terms of Service: Always check the terms of service before scraping a website. Respecting these guidelines helps maintain a fair relationship with content providers.
- User Privacy Matters: Websites often host personal information about their users. Scraping this data without consent can lead to privacy violations, which are unethical and potentially illegal.
Another key aspect to consider is the impact of scraping on website performance. Heavy scraping can strain a site's resources, causing problems for the website itself and its users.
- Server Load: Making too many requests too quickly can slow down or even crash a website, affecting legitimate users trying to access the content.
- Risk of Being Blocked: Websites may detect aggressive scraping behavior and block your IP address, making it impossible to access the site in the future.
Data Extraction Solutions Company: AutoScraping
At AutoScraping, we know that data extraction can be tricky. Many businesses face hurdles when trying to gather valuable information from websites.
Our mission is to make this process easier and more reliable. We provide tools that help businesses extract data without the usual complications.
- Tailored Solutions: Our platform offers customized options for various industries. Whether you need data from e-commerce sites, real estate listings, or social media, we've got you covered.
- Scalable Services: No matter your company size, our solutions can grow with you. We provide both one-time extraction and ongoing support to fit your specific needs.
What really sets AutoScraping apart is our focus on data accuracy. We understand that businesses need reliable information to make decisions. Our technology ensures that the data extracted is clean and structured, so you can skip the tedious cleanup process.
- Up-to-Date Data: We actively monitor website changes, which helps ensure that the data you receive is current and precise. This reduces the chances of working with outdated or incorrect information.
- Support When You Need It: Our team is here to help. If you encounter any issues, you can count on us for guidance and assistance.
FAQS: Are There Disadvantages of Web Scraping?
What are the disadvantages of scraping?
The disadvantages of web scraping include potential legal issues, as many sites have terms of service that explicitly prohibit it. This can lead to lawsuits or account bans.
What are the dangers of web scraping?
The dangers of web scraping encompass security vulnerabilities, as poorly designed scrapers can expose sensitive data or create entry points for cyberattacks. Moreover, aggressive scraping can overload a website's server, causing downtime.
What are the cons of screen scraping?
Cons of screen scraping include its dependency on the visual layout of a website, which can change frequently. This results in a lack of consistency and may lead to incomplete or inaccurate data extraction.



